Rassal orman (Random Forest) hem regresyon hem de sınıflandırma problemlerine uygulanabilir olmasından dolayı popüler makine öğrenmesi modellerinden biridir. Bizim analizini yapacağımız Random forest regresyonu birden fazla karar ağacını kullanarak daha uyumlu modeller üreterek isabetli tahminlerde bulunmaya yarayan bir regresyon modelidir. Yani, birden fazla üretilen karar ağacının ürettiği tahminlerin bir araya getirilerek değerlendirilmesine dayanır.
Rassal orman modeli veri setinden rassal olarak 10'larca 100'lerce farklı alt-kümeler seçiyor ve bunları eğitiyor. Bu yöntemle 100'lerce karar ağacı oluşturuluyor ve her bir karar ağacı bireysel olarak tahminde bulunuyor. Bunun sonucunda karar ağaçlarının tahminlerinin ortalamasını alıyoruz.
Rassal orman modeli veri setinden rassal olarak 10'larca 100'lerce farklı alt-kümeler seçiyor ve bunları eğitiyor. Bu yöntemle 100'lerce karar ağacı oluşturuluyor ve her bir karar ağacı bireysel olarak tahminde bulunuyor. Bunun sonucunda karar ağaçlarının tahminlerinin ortalamasını alıyoruz.

Random forest regresyonda en önemli nokta; modelin üretmiş olduğu ağaçlar ayrılırken/çoklanırken sadece rassal değişkenler kullanılır. Böylece modelin üretmiş olduğu ağaçlar arasındaki korelasyon azalır. Yani, model birbirine yakın olmayan ağaçlar üretir ve böylece overfitting problemini ortadan kaldırmış olur.
Ağaç oluşturmada sadece verinin 2/3’ü kullanılır. Dışarıda kalan veri ağaçların performans değerlendirmesi ve değişken öneminin belirlenmesi için kullanılır. Nihai tahmin için ağaçlardan tahmin değerleri talep edilirken her bir ağacın daha önce hesaplanan hata oranları göz önüne alınarak ağaçlara ağırlık verilir.
Ağaç oluşturmada sadece verinin 2/3’ü kullanılır. Dışarıda kalan veri ağaçların performans değerlendirmesi ve değişken öneminin belirlenmesi için kullanılır. Nihai tahmin için ağaçlardan tahmin değerleri talep edilirken her bir ağacın daha önce hesaplanan hata oranları göz önüne alınarak ağaçlara ağırlık verilir.

Analizimde yine “Hitters” verisini kullanacağım. Her zaman olduğu gibi önce verimi hazırlıyorum.

Random forest modelim için sklearn kütüphanesinden RandomForestRegressor modülünü çağırıyorum. Modelimi fit ettikten sonra model argümanlarını inceliyorum. Burada en önemli iki argüman ortaya çıkacak ağaç sayısını gösteren “n_estimators” ile ağaçları bölecek rassal değişken adedini gösteren “max_features” argümanlarıdır.

Modeli kurduktan sonra tahmin kısmına geçiyorum. Burada her analizde olduğu gibi test setimi tahmin et dedikten sonra test hatamı hesaplıyorum ve model tuning kısmına geçiyorum.

Model tuning kısmında benim için en önemli 3 parametre için değerleri girdikten sonra buna göre modelime 10 katlı cross validation uyguluyorum.

Cross validation işleminden sonra modelden çıkan en optimum parametre değerlerini getir diyorum. Buna göre derinlik 8, değişken adedi 3, tahminci adedim ise 200 çıkıyor. Daha sonra bu değerler üzerinden modeli tekrar tune ediyorum. Modeli fit ettikten sonra test setimi tahmin et dedikten sonra test hatamı hesaplıyorum.

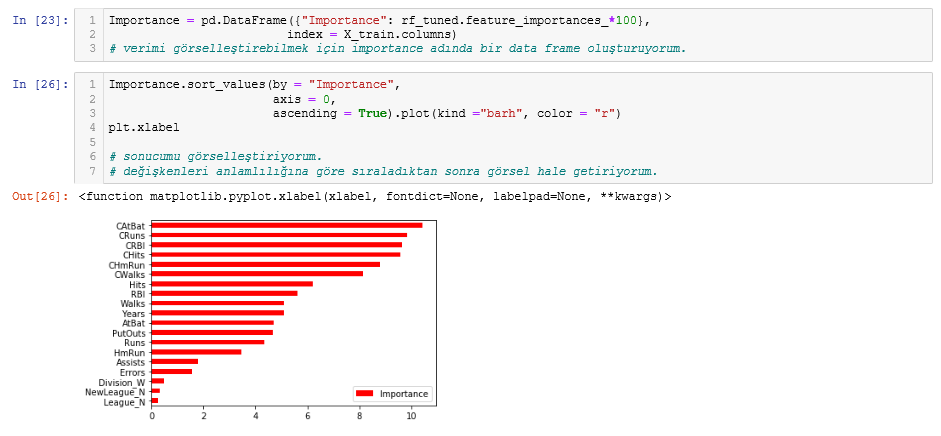
Modelimi bitirdim fakat model çıktılarını görsel olarak göstermek istiyorum. Bunun için importance adında bir data frame oluşturuyorum. Burada değişkenlerin önem düzeyini göstermek için önce sıralıyorum sonra da grafik olarak görselleştiriyorum.
Yorumlar
Yorum Gönder