Bir sağlık kulübü (healthclub) insanların neden healthclubu tercih ettiğini araştırmak üzere 18 sorudan oluşan bir anket yapıyor. Buradaki amaç; insanların healthclub tercihi yaparken hangi faktörlere önem verdiğini tespit etmek. Bu noktada; SPSS’in Faktör Analizi’ni kullanacağız. Faktör analizinin cluster’dan (kümeleme) farkı ; cluster müşterileri (bireyleri) sınıflara ayırırken, faktör analizi değişkenleri sınıflandırıp bunları ana başlıklara ayırıyor. Bu sebeple; cluster analizi yapmadan önce faktör analizini yapmak daha sağlıklı sonuçlar alınmasını sağlayacaktır.

Faktör Analizini yapmak için SPSS’in Analyze kısmında Dimension Reduction’u ve Factor’ü seçiyoruz.

18 adet soruyu variable kısmına atıyoruz.

Descriptives kısmından “KMO and Bartlett’s test of sphericity” işaretliyorum.

Extraction kısmında “Principal Components” seçiyorum ve Eigenvalue’yi 1 yapıyorum.

Rotation kısmında Method’u “Varimax” olarak seçip, Maximum iteration for Convergence’yi 25 yapıyorum.

Şimdi analizimi çalıştırabilirim.

Analizin sonucunda ilk bakacağımız tablo KMO and Bartlett Test tablosu olacaktır. KMO kısaca bizim datamızın faktör analizi yapmaya uygun olup olmadığını gösterir. KMO değeri 0 ile 1 arasında bir değer almalıdır. Değer 1’e ne kadar yaklaşırsa o kadar iyi olmakla birlikte, bu aralığın ideali 0,7 ve 0,9 arasındadır. Ancak, 0,9 üzeri şüphe yaratır. Bununla birlikte; Bartlett değeri ne kadar yüksekse o kadar iyidir ama bunun için belirlenmiş bir eşik değeri bulunmamaktadır. Burda KMO değerim 0.749 gibi iyi bir değer. Bartlett ise 6858.550 gibi oldukça yüksek bir değer. Ayrıca, sig değerim 0,05’ten küçük olduğu için verim analiz için anlamlı.

İkinci bakacağımız tablo ise Communalities. Burada “Extraction” değerlerini inceliyoruz. Extraction bize her bir itemın faktör analizine girdiğinde sağlayacağı katkıyı gösterir. Extraction değeri de 0 ile 1 arasında bir değer alır ve 1’e ne kadar yaklaşırsa o kadar iyidir. Burada 0,5 üstü değerler iyi kabul edilmekle birlikte kimi durumlarda 0,4’e kadar inilmektedir. Burada son soru hariç tüm değerler 0,5 üzeri çıkıyor. Sadece buradan yola çıkarak son sorunun analizimde sorun çıkaracağı yorumunu yapabilirim.

Üçüncü bakacağımız tablo ise “Total Variance Explained” tablosu. Analize başlamadan önce Extraction kısmında Eigemvalue’yi 1 ve üstü yarat demiştik. Buna göre SPSS, eigemvalue’si 1’den büyük olan 5 adet faktör yarattı. Yani analize göre 18 item (soru) 5 adet faktör altında toplanıyor. Tablonun “Cumulative” kısmında ise bu 5 faktörün toplam varyansın %83,6’sını oluşturduğunu görüyorum. Buradaki cumulative değeri en az %50 olmalı. Ancak, bizim analizimizde bu değer %83,6 gibi oldukça yüksek bir oran. Yani, bu 5 faktör healthclub tercihini açıklamaya yeterli düzeyde.

Dördüncü bakacağımız tablo ise “Rotated Component Matrix” tablosu. Bu tablo, her bir itemın altına hangi soruyla ilişkili olduğunu getirir ve minimum 0,4 değerini alır. Dolayısıyla, bu değerin altındaki değerler analizimin sağlıklı sonuç vermesini engeller. Son soru bu değerin çok yakınında 0,410 olduğu için bu soruyu çıkarıp analizi tekrar çalıştıracağım.

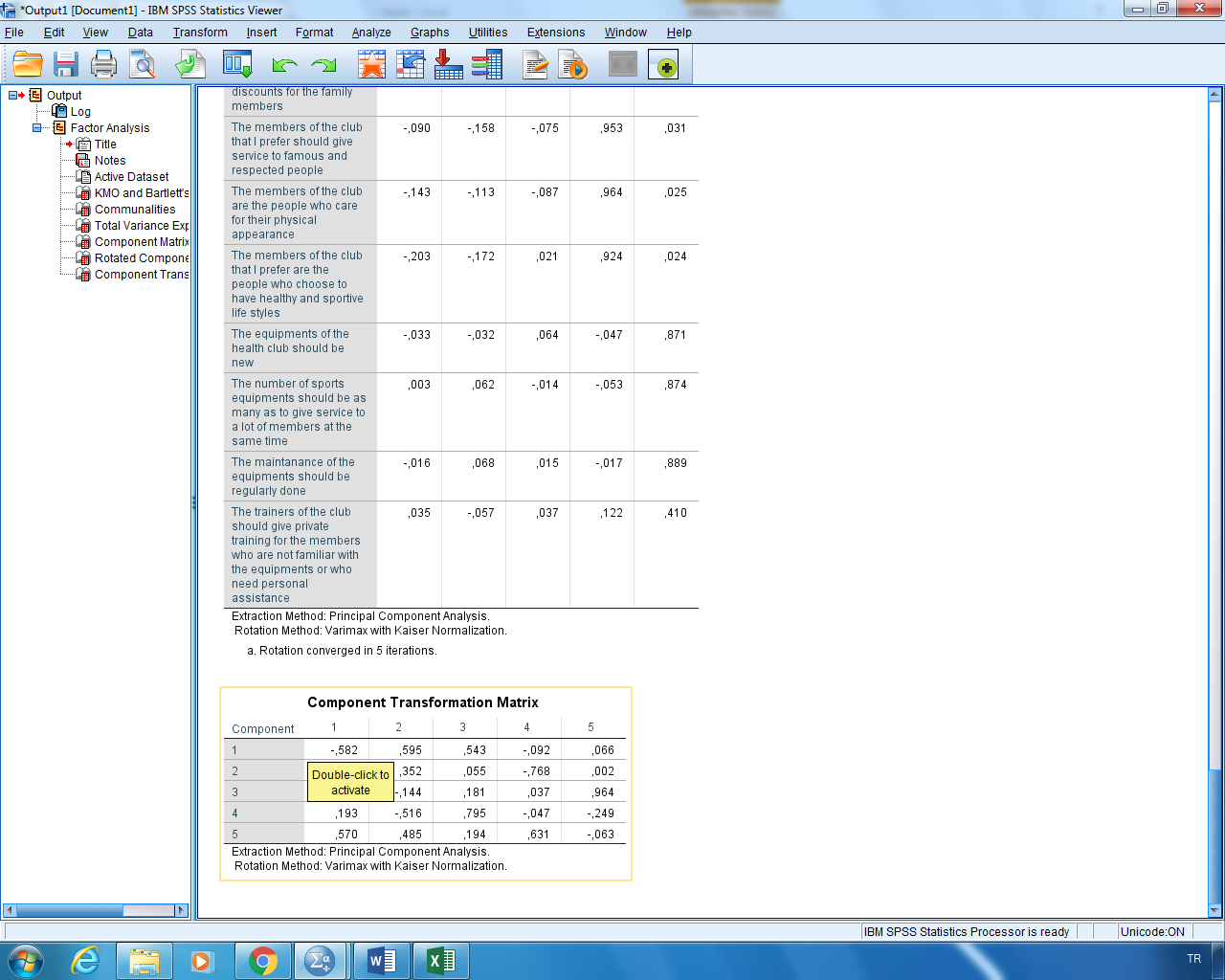
Son soruyu çıkarıp Options kısmında “Sorted by size” diyorum ki tabloyu daha kolay yorumlayabileyim.

İlk olarak yine KMO and Bartlett’s Test tablosuna bakıyorum. Tabloda herhangi bir değişiklik olmamış.

Communalities’de de bir sıkıntı görünmüyor.

Total Variance Explained tablosunda faktörlerin açıklama gücünün %87,8’e yükseldiğini görüyorum.


Rotated Component Matrix tablosundaki değerler bir öncekiyle aynı. Şimdi bu tabloya göre 5 adet component’ı soruları açıklama gücüne göre yorumlayıp isimlendirebilirim. Bunun için Variable View kısmına gelip faktörlerin üzerinde çift tıklayıp bunları isimlendiriyorum. 1. Gruba ambiance, 2. Gruba service, 3. Gruba price, 4. Gruba community, 5. Gruba ise equipment diyorum. Output’a dönüp, 1. Gruba hangi sorular girmişse onları f1 (yani 1. Grup) karşısına yazıyorum. F1 ambiyansı control c ile kopyalıyorum, transform diyorum, compute veri seçiyoruz, target variables kısmına ctrl v diyip yapıştırıyorum yani “f1 ambiyans”, numeric expression kısmına: parantez açıyoruz, sırayla itemları seçip + diyerek ilerliyoruz parantesi kapatıp bölü 4 diyoruz çünkü 4 item var. Parantez burada önemli. (HC1+HC2+HC3+HC4)/4. Ok diyerek ilerliyoruz. Data viewa dönüyorum f1 ambiyans değerinin oluşturulduğunu görüyorum. Dataya dönüyorum itemların value kısmında strongly agree olan kısımları faktörlerin yanına ctrl v deyip yapıştırıyorum, her birini nominalden scale çeviriyorum ve kaydedip kapatıyorum.
Yorumlar
Yorum Gönder